LLMs like ChatGPT, Claude or LLaMA are brilliant generalists — but not specialists.
Fine-tuning changes that. Instead of spending millions to train a model from scratch, you can adapt existing models to excel in medicine, law, customer support, or coding — for just hundreds or thousands of dollars.
✨ KEY TAKEAWAYS ✨
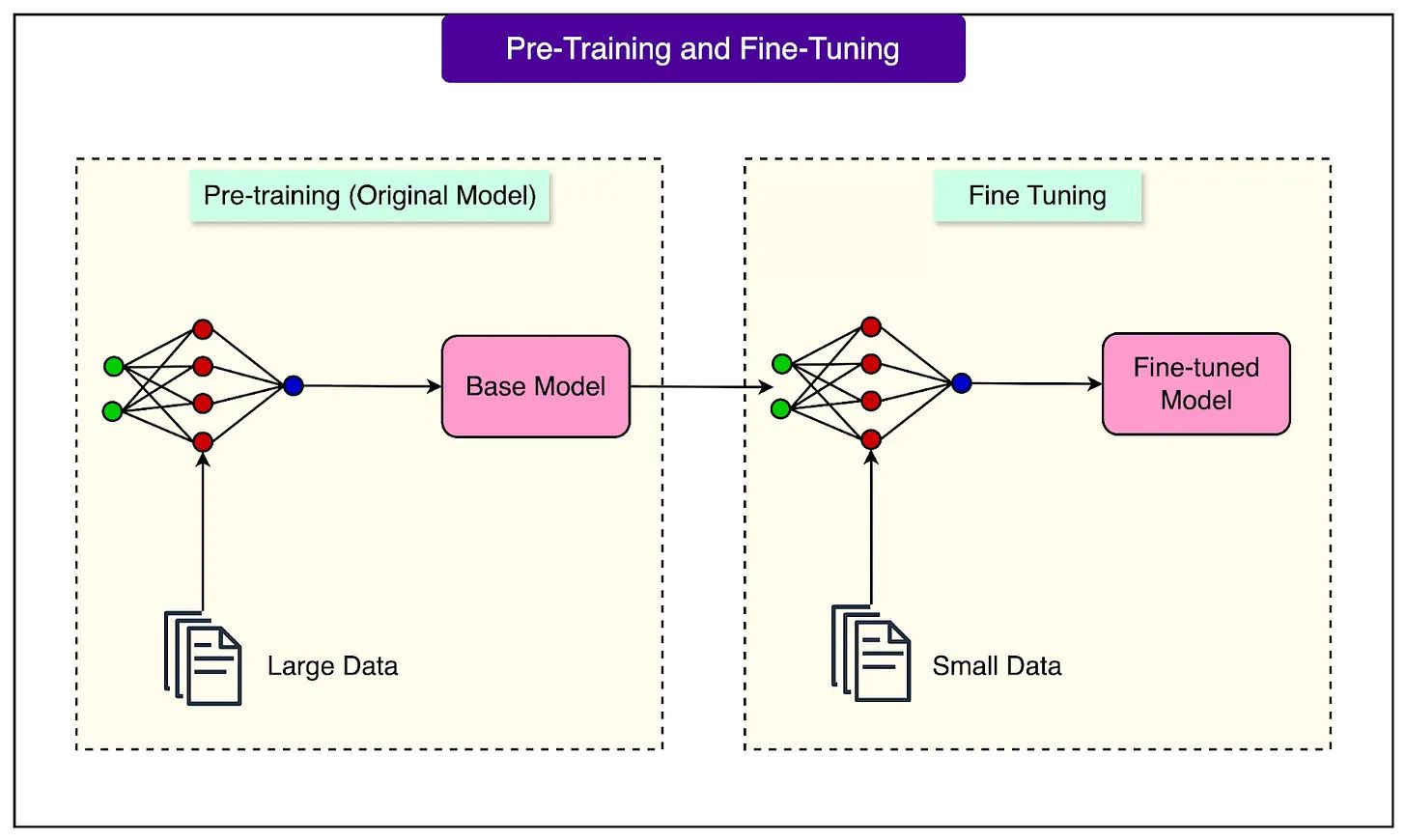
1. Pre-training = general knowledge.
Models are trained on internet-scale data, powerful but unfocused.
2. Fine-tuning = specialization.
Adjusts model “weights” to fit your context and tasks.
3. Types of fine-tuning include:
Instruction Fine-Tuning, RLHF (human feedback), and Domain Adaptation.
4. Efficiency breakthroughs:
-LoRA updates less than 0.1% of parameters, cutting costs massively.
-QLoRA enables fine-tuning giant models on consumer GPUs.
-DoRA separates weight updates for even better efficiency.
💡 ADVICE FOR TEAMS💡
1. Start small, focus on quality data — 1,000 good examples beat 100k noisy ones.
2. Pick the right method — LoRA/QLoRA work for most cases, full fine-tuning only if mission-critical.
3. Plan deployment — LoRA adapters let you hot-swap specializations instantly.
4. Validate continuously — prevent overfitting with clean test sets.
👉 Fine-tuning democratizes AI.
What used to be limited to tech giants is now accessible to startups, researchers, and even hobbyists.
Expect an explosion of specialized AI assistants across industries. 🕶️